

构建外部信息召回神器:实现信息检索的终极利器
在当今信息爆炸的时代,构建一个强大的外部信息召回系统对于许多企业和研究团队来说是至关重要的。这种系统可以帮助用户从海量数据中快速准确地检索到所需信息,为决策和研究提供支持。本文将探讨如何利用大型模型来打造这样一个外部信息召回神器,使其达到最佳效果。
理解外部信息召回系统的基本构成
外部信息召回系统的核心目标是根据用户的查询从外部来源(如互联网、数据库、文档等)中检索相关信息。其主要组成部分包括:
1.
信息抽取与处理
:从原始数据源中抽取并清洗信息,以便后续的检索和分析。2.
索引与存储
:将处理后的信息建立索引并进行高效存储,以便快速检索。3.
查询处理与优化
:接收用户的查询,进行语义理解、查询扩展等处理,优化检索效果。4.
结果展示与反馈
:将检索到的信息按照用户需求进行排序和展示,同时允许用户反馈以优化系统性能。利用大型模型的优势
近年来,随着自然语言处理技术的发展,大型预训练模型(如GPT4等)已经在各种信息检索任务中展示出了强大的性能。它们能够理解语义、处理复杂的查询,并生成高质量的文本响应。利用这些模型构建外部信息召回系统有以下几个关键优势:
语义理解与上下文感知
:大型模型能够理解语义和上下文,能够更好地处理用户的查询,包括同义词、语法变化和语境中的变化。
多源信息融合
:通过模型的多模态能力,可以整合来自不同来源(文本、图像、视频等)的信息,提供更丰富的检索结果。
个性化和实时性
:可以根据用户的历史查询和行为进行个性化推荐,同时能够快速适应新的数据和情境。
效率和扩展性
:通过模型的并行计算和高效算法,可以实现快速的查询响应和大规模数据的处理能力。构建步骤与关键技术
1. 数据采集与预处理
需要从外部数据源采集数据,这可能涉及到网络爬虫、API接口调用或者数据集成等方式。数据采集后需要进行清洗、去重、标准化等预处理步骤,确保数据质量和一致性。
2. 数据索引与存储
将预处理后的数据建立索引并进行高效存储是信息召回系统的基础。常见的技术包括倒排索引、分布式存储系统(如Elasticsearch、Apache Solr等)等,确保数据的快速检索能力。
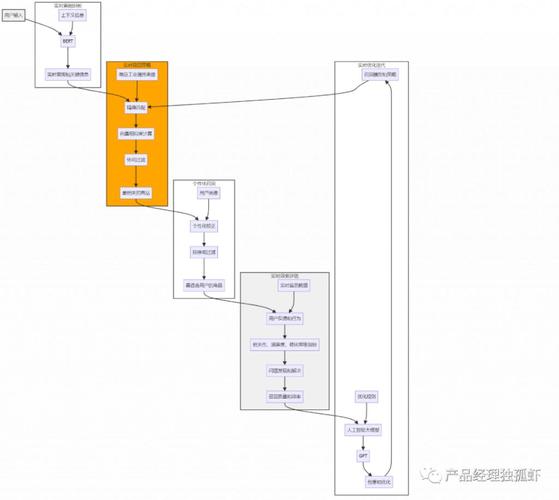
3. 模型选择与集成
选择合适的大型预训练模型(如GPT4、BERT等),根据具体任务进行微调或者使用迁移学习的方式,以适应特定的信息召回需求。模型的集成可以通过服务化部署或者云端API方式实现。
4. 查询处理与优化
接收用户的查询后,需要进行语义理解、查询扩展和相关性评分等处理。这一步通常涉及到自然语言处理技术、信息检索算法(如BM25、TFIDF等)的应用,以及模型输出的后处理。
5. 结果展示与反馈
将检索到的信息按照相关性排序并展示给用户,同时提供反馈机制,收集用户的点击、满意度等信息,用于优化系统的检索策略和模型性能。
持续优化与评估
建立外部信息召回系统后,需要进行持续的优化和评估工作。这包括监控系统性能、收集用户反馈、分析查询日志等,以不断改进模型精度、系统响应速度和用户体验。
结论
通过利用大型预训练模型,可以构建出功能强大、效率高的外部信息召回神器,为用户提供准确、个性化的信息检索服务。关键在于充分利用模型的语义理解能力和多模态整合能力,同时结合传统的信息检索技术,构建出既实用又具有扩展性的系统。随着人工智能技术的进一步发展,外部信息召回系统将不断演进,成为信息检索领域的"ultimate"工具。
 井合
井合






